|
Название локации
|
Расположение
|
Уровень ЦОД
|
| Москва SLAVA |
Россия, г. Москва |
Фактический Tier III |
| Москва OST |
Россия, г. Москва |
Фактический Tier III |
| Таллин EST |
Эстония |
Фактический Tier III |
| Ташкент |
Узбекистан |
|
| Алматы |
Казахстан |
|
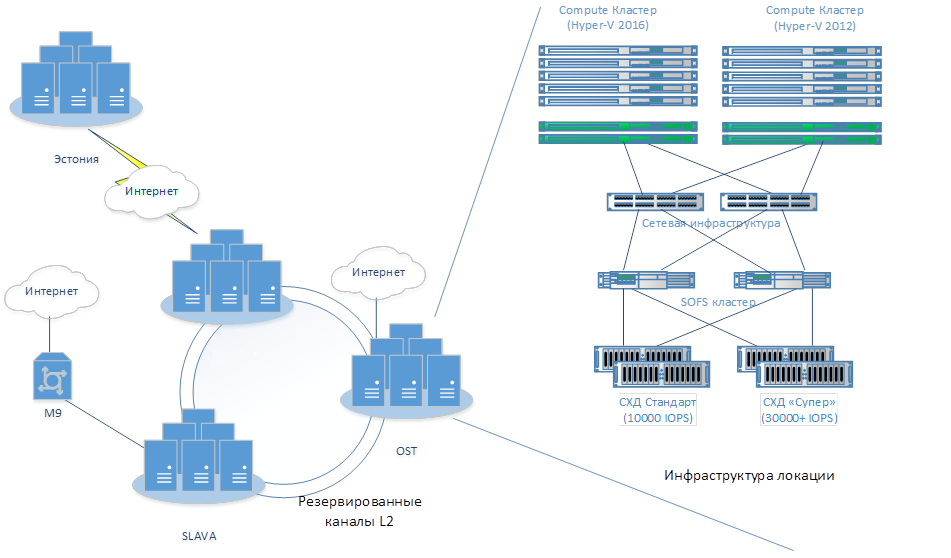
Московские локации объединены высокоскоростными оптическими каналами связи с уровнем резервирования N+1, то есть фактически все ресурсы Облакотеки находятся в единой локальной сети, что позволяет осуществлять управление и организовать рабочие процессы в прозрачном режиме, как будто все оборудование расположено на одной большой площадке, в том числе организовывать кросс-бекапы, строить географически распределенные кластеры и прозрачно мигрировать ресурсы между локациями.
Выход в интернет осуществляется через нескольких провайдеров-аплинков: Гарс, Вестколл, Реконн. Таким образом обеспечивается не только техническая, но и «юридическая» независимость.
Загрузка интернет-каналов поддерживается на уровне 70% от максимальных пиковых значений, возможно его кратное расширение на уровне настроек без необходимости замены сетевого оборудования. Облакотека имеет присутствие на точке обмена трафика Dataline-IX и ММТС-9, что позволяет организовывать выделенные каналы связи из офиса клиентов до их облака в Облакотеке.
Для различных задач используется сетевое оборудование класса Datacenter: Mellanox, Juniper, Huawei, Brocade. Внутренний трафик, трафик СХД, внешний трафик полностью изолированы. Все сетевые устройства функционируют в кластерном режиме в режиме резервирования 2N.
IaaS платформа
Общая архитектура
| Кластер |
Локация |
Платформа |
Сеть |
СХД |
| OST2012 |
OST |
Hyper-V 2012 R2 |
HNV, vLAN |
Архив,
SSD Standard,
SSD Супер
|
| OST2016 |
OST |
Hyper-V 2016 |
SDN2 **, vLAN |
| SLAVA |
SLAVA |
Hyper-V 2016 |
SDN2, vLAN |
| EST |
EST |
Hyper-V 2019 |
SDN2 |
SSD Standard (локальные) |
* Виртуальные сети HNV (Hyper-V Network Virtualization) – это виртуальные сети, которые используют технологию NVGRE http://en.wikipedia.org/wiki/NVGRE и реализованы на основе гипервизора Hyper-V.
** Программно-определяемая сеть (SDN) позволяет централизованно настраивать и контролировать физические и виртуальные сетевые устройства, например маршрутизаторы, коммутаторы и шлюзы в центре обработки данных. Вы можете использовать существующие устройства, совместимые с SDN, чтобы обеспечить более глубокую интеграцию между виртуальной сетью и физической сетью.
В каждой локации расположены один или несколько кластеров вычислительных узлов на платформе Hyper-V 2012 R2 или Hyper-V 2016. Все кластеры подключены к СХД по высокоскоростным каналам. Каждая СХД сегментирована по пулам ресурсов разной производительности (см. таблицу). При размещении виртуальных машин на кластерах локальные диски вычислительных узлов не используются (кроме кластера EST).
Помимо этого, эксплуатируется несколько специализированных выделенных узлов максимальной производительности – «молотилок».
|
1
Вычислительные узлы
Кластерная организация вычислительных узлов, на которых размещаются ВМ клиентов, позволяет гарантировать максимальный uptime работы любой виртуальной машины
при выходе из строя любого вычислительного узла (3-5 минут на перезагрузку). Все кластеры имеют избыточность N+2, что позволяет как проводить профилактические работы без приостановки сервиса, так и гарантировать SLA 99,9% даже в случае падения узла во время проведения профилактических работ на другом узле. Облакотека обеспечивает качество в основном за счет избыточности, поэтому в качестве узлов
используются стандартные серверы Dell, Lenovo, Supermicro.
В вычислительных узлах стоят разные по производительности процессоры, поэтому есть возможность как подобрать оптимальную производительность, так и получить гарантированные ресурсы ядер процессора и добиться
нужной мощности виртуальной машины по разумной стоимости. Мы последовательно выполняем модернизацию наших вычислительных узлов. Устаревшая платформа виртуализации
2012 выводится из эксплуатации и заменяется на новую, поэтому кластеры на платформе Hyper-V 2012 закрыты на заведение новых облаков (подписок), но создание новых ВМ в рамках уже заведенных облаков всё ещё возможно...
|
2
СХД
Внутри одной локации кластеры могут иметь доступ к любым СХД, что дает возможность размещать диски виртуальных машин на любых СХД. Доступ к SAN-сетям построен с использованием технологии SOFS (scale out file server), причём Облакотека использует только отказоустойчивые, масштабируемые кластеры SOFS, в которых все компоненты задублированы. В качестве конечных СХД устройств используются отказоустойчивые накопители (двухконтроллерные дисковые полки) реализованные на оборудовании DELL и Infortrend. Со стороны пользователя СХД сегментирована по производительности на 3 группы Super, STANDARD, Archive. На каждую группу гарантированно предоставляется производительность не ниже заявленных значений IOPS. Облакотека с 2017 года вводит в эксплуатацию только SSD диски, но при этом для СХД частично используются и диски типа HDD. Для дисков типа «Архив» используются отказоустойчивые программные СХД на основе технологии Storage Spaces. Для уменьшения задержек ввода\вывода реализована поддержка технологии SMB Direct (RDMA), используются коммутаторы и сетевые адаптеры компании Mellanox, которые поддерживают эту технологию.
|
|
3
Сетевые сервисы
Использование технологий виртуальных сетей HNV или SDN2 позволяет создавать виртуальные клиентские сети, которые
могут быть распределены между локациями.
Прозрачная сетевая коммуникация таких решений даёт возможность строить геораспределённые отказоустойчивые решения нашим клиентам.
|
4
Резервирование
Во всех локациях Облакотеки внедрена отдельная система резервного копирования. Для большинства систем используется кросс-бекап в другую локацию. Система резервного копирования в обязательном порядке резервирует инфраструктурные данные, необходимые для функционирования платформы, а также предоставляет возможность резервирования данных виртуальных машин клиентов в качестве дополнительной услуги с самостоятельным управлением глубиной бекапа.
Помимо этого, в Облакотеке на уровне инфраструктуры развернута система теплого резервирования (DR, Disaster-recovery), которая позволяет в случае катастрофы одной локации восстановить работоспособность всей клиентской системы в другой локации гарантированно за 0,5-2 часа. Возможна репликация систем из офиса клиента в Облакотеку и в обратную сторону.
|
|